描述符池和集合
描述符池
描述符集不能直接创建,它们必须像命令缓冲区一样从池中分配。描述符集的等价物不出所料地称为描述符池。我们将编写一个新的函数 createDescriptorPool 来设置它。
void initVulkan() {
...
createUniformBuffers();
createDescriptorPool();
...
}
...
void createDescriptorPool() {
}我们首先需要使用 VkDescriptorPoolSize 结构描述我们的描述符集将包含哪些描述符类型以及它们的数量。
VkDescriptorPoolSize poolSize{};
poolSize.type = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
poolSize.descriptorCount = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);我们将为每一帧分配一个这些描述符。此池大小结构由主要的 VkDescriptorPoolCreateInfo 引用。
VkDescriptorPoolCreateInfo poolInfo{};
poolInfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_POOL_CREATE_INFO;
poolInfo.poolSizeCount = 1;
poolInfo.pPoolSizes = &poolSize;除了可用的单个描述符的最大数量外,我们还需要指定可以分配的最大描述符集数量。
poolInfo.maxSets = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);该结构有一个可选标志,类似于命令池,用于确定是否可以释放单个描述符集:VK_DESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SET_BIT。我们创建描述符集后不会再对其进行操作,因此我们不需要此标志。您可以将 flags 保留为其默认值 0。
VkDescriptorPool descriptorPool;
...
if (vkCreateDescriptorPool(device, &poolInfo, nullptr, &descriptorPool) != VK_SUCCESS) {
throw std::runtime_error("failed to create descriptor pool!");
}添加一个新的类成员来存储描述符池的句柄,并调用 vkCreateDescriptorPool 来创建它。
描述符集
我们现在可以分配描述符集本身。为此添加一个 createDescriptorSets 函数
void initVulkan() {
...
createDescriptorPool();
createDescriptorSets();
...
}
...
void createDescriptorSets() {
}描述符集分配使用 VkDescriptorSetAllocateInfo 结构描述。您需要指定要从中分配的描述符池、要分配的描述符集数量以及要基于它们的描述符集布局。
std::vector<VkDescriptorSetLayout> layouts(MAX_FRAMES_IN_FLIGHT, descriptorSetLayout);
VkDescriptorSetAllocateInfo allocInfo{};
allocInfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_ALLOCATE_INFO;
allocInfo.descriptorPool = descriptorPool;
allocInfo.descriptorSetCount = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);
allocInfo.pSetLayouts = layouts.data();在我们的例子中,我们将为飞行中的每一帧创建一个描述符集,所有描述符集都具有相同的布局。不幸的是,我们确实需要布局的所有副本,因为下一个函数需要一个与集合数量匹配的数组。
添加一个类成员来保存描述符集句柄,并使用 vkAllocateDescriptorSets 分配它们。
VkDescriptorPool descriptorPool;
std::vector<VkDescriptorSet> descriptorSets;
...
descriptorSets.resize(MAX_FRAMES_IN_FLIGHT);
if (vkAllocateDescriptorSets(device, &allocInfo, descriptorSets.data()) != VK_SUCCESS) {
throw std::runtime_error("failed to allocate descriptor sets!");
}您不需要显式清理描述符集,因为它们会在描述符池销毁时自动释放。对 vkAllocateDescriptorSets 的调用将分配描述符集,每个描述符集都有一个统一缓冲区描述符。
void cleanup() {
...
vkDestroyDescriptorPool(device, descriptorPool, nullptr);
vkDestroyDescriptorSetLayout(device, descriptorSetLayout, nullptr);
...
}现在已经分配了描述符集,但仍需要配置其中的描述符。我们现在将添加一个循环来填充每个描述符
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
}引用缓冲区的描述符(例如我们的统一缓冲区描述符)使用 VkDescriptorBufferInfo 结构进行配置。此结构指定缓冲区以及其中包含描述符数据的区域。
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
VkDescriptorBufferInfo bufferInfo{};
bufferInfo.buffer = uniformBuffers[i];
bufferInfo.offset = 0;
bufferInfo.range = sizeof(UniformBufferObject);
}如果您像我们在这种情况下一样覆盖整个缓冲区,那么也可以将 VK_WHOLE_SIZE 值用于范围。描述符的配置使用 vkUpdateDescriptorSets 函数更新,该函数接受 VkWriteDescriptorSet 结构的数组作为参数。
VkWriteDescriptorSet descriptorWrite{};
descriptorWrite.sType = VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET;
descriptorWrite.dstSet = descriptorSets[i];
descriptorWrite.dstBinding = 0;
descriptorWrite.dstArrayElement = 0;前两个字段指定要更新的描述符集和绑定。我们给统一缓冲区绑定索引 0。请记住,描述符可以是数组,因此我们还需要指定要更新的数组中的第一个索引。我们没有使用数组,因此索引只是 0。
descriptorWrite.descriptorType = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
descriptorWrite.descriptorCount = 1;我们需要再次指定描述符的类型。可以在一个数组中一次更新多个描述符,从索引 dstArrayElement 开始。descriptorCount 字段指定要更新的数组元素的数量。
descriptorWrite.pBufferInfo = &bufferInfo;
descriptorWrite.pImageInfo = nullptr; // Optional
descriptorWrite.pTexelBufferView = nullptr; // Optional最后一个字段引用一个包含 descriptorCount 结构的数组,该结构实际上配置了描述符。根据描述符的类型,您实际上需要使用这三个中的哪一个。pBufferInfo 字段用于引用缓冲区数据的描述符,pImageInfo 用于引用图像数据的描述符,pTexelBufferView 用于引用缓冲区视图的描述符。我们的描述符基于缓冲区,因此我们使用 pBufferInfo。
vkUpdateDescriptorSets(device, 1, &descriptorWrite, 0, nullptr);使用 vkUpdateDescriptorSets 应用更新。它接受两种类型的数组作为参数:VkWriteDescriptorSet 数组和 VkCopyDescriptorSet 数组。后者可用于将描述符相互复制,正如其名称所示。
使用描述符集
我们现在需要更新 recordCommandBuffer 函数,以使用 vkCmdBindDescriptorSets 将每一帧的正确描述符集绑定到着色器中的描述符。这需要在 vkCmdDrawIndexed 调用之前完成
vkCmdBindDescriptorSets(commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, pipelineLayout, 0, 1, &descriptorSets[currentFrame], 0, nullptr);
vkCmdDrawIndexed(commandBuffer, static_cast<uint32_t>(indices.size()), 1, 0, 0, 0);与顶点缓冲区和索引缓冲区不同,描述符集对于图形管线不是唯一的。因此,我们需要指定是否要将描述符集绑定到图形管线或计算管线。下一个参数是描述符所基于的布局。接下来的三个参数指定第一个描述符集的索引、要绑定的集合数量以及要绑定的集合数组。我们稍后会回到这一点。最后两个参数指定用于动态描述符的偏移量数组。我们将在以后的章节中介绍这些。
如果你现在运行你的程序,你会注意到不幸的是没有任何东西是可见的。问题在于,由于我们在投影矩阵中进行了 Y 翻转,顶点现在是以逆时针顺序而不是顺时针顺序绘制的。这会导致背面剔除生效,并阻止任何几何图形被绘制。转到 createGraphicsPipeline 函数,并修改 VkPipelineRasterizationStateCreateInfo 中的 frontFace 来纠正这个问题。
rasterizer.cullMode = VK_CULL_MODE_BACK_BIT;
rasterizer.frontFace = VK_FRONT_FACE_COUNTER_CLOCKWISE;再次运行你的程序,你现在应该看到以下内容
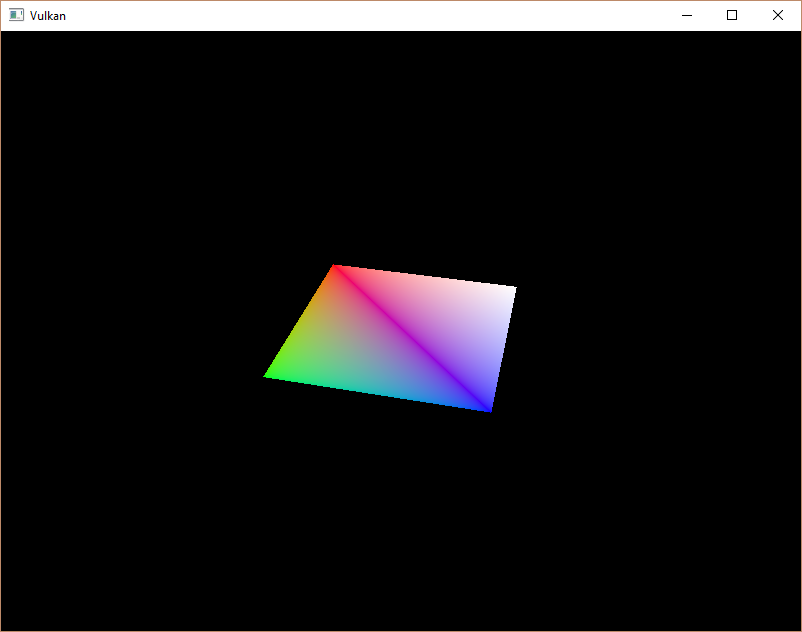
矩形已经变成了一个正方形,因为投影矩阵现在纠正了宽高比。updateUniformBuffer 负责屏幕大小调整,所以我们不需要在 recreateSwapChain 中重新创建描述符集。
对齐要求
到目前为止,我们忽略了一件事,那就是 C++ 结构中的数据应该如何与着色器中的 uniform 定义匹配。在两者中使用相同的类型似乎是很明显的。
struct UniformBufferObject {
glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};
layout(binding = 0) uniform UniformBufferObject {
mat4 model;
mat4 view;
mat4 proj;
} ubo;然而,这并非全部。例如,尝试修改结构体和着色器,使其如下所示
struct UniformBufferObject {
glm::vec2 foo;
glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};
layout(binding = 0) uniform UniformBufferObject {
vec2 foo;
mat4 model;
mat4 view;
mat4 proj;
} ubo;重新编译你的着色器和程序并运行它,你会发现你到目前为止一直在使用的彩色正方形消失了!那是因为我们没有考虑到对齐要求。
Vulkan 希望你结构中的数据以一种特定的方式在内存中对齐,例如
-
标量必须按 N 对齐(对于 32 位浮点数,N = 4 字节)。
-
一个
vec2必须按 2N 对齐(= 8 字节) -
一个
vec3或vec4必须按 4N 对齐(= 16 字节) -
一个嵌套结构必须按其成员的基本对齐方式对齐,并向上舍入到 16 的倍数。
-
一个
mat4矩阵必须与一个vec4具有相同的对齐方式。
你可以在规范中找到完整的对齐要求列表。
我们最初的着色器只有三个 mat4 字段,已经满足了对齐要求。由于每个 mat4 的大小为 4 x 4 x 4 = 64 字节,model 的偏移量为 0,view 的偏移量为 64,proj 的偏移量为 128。所有这些都是 16 的倍数,这就是它能正常工作的原因。
新的结构体以一个 vec2 开头,它只有 8 个字节大小,因此会扰乱所有的偏移量。现在 model 的偏移量为 8,view 的偏移量为 72,proj 的偏移量为 136,它们都不是 16 的倍数。要解决这个问题,我们可以使用 C++11 中引入的 alignas 说明符
struct UniformBufferObject {
glm::vec2 foo;
alignas(16) glm::mat4 model;
glm::mat4 view;
glm::mat4 proj;
};如果你现在编译并再次运行你的程序,你应该会看到着色器再次正确接收其矩阵值。
幸运的是,有一种方法可以让你大部分时候不必考虑这些对齐要求。我们可以在包含 GLM 之前定义 GLM_FORCE_DEFAULT_ALIGNED_GENTYPES
#define GLM_FORCE_DEFAULT_ALIGNED_GENTYPES
#include <glm/glm.hpp>这将强制 GLM 使用一个已经为我们指定了对齐要求的 vec2 和 mat4 版本。如果你添加此定义,那么你可以删除 alignas 说明符,你的程序仍然可以工作。
不幸的是,如果你开始使用嵌套结构,这种方法可能会失效。考虑以下 C++ 代码中的定义
struct Foo {
glm::vec2 v;
};
struct UniformBufferObject {
Foo f1;
Foo f2;
};以及以下着色器定义
struct Foo {
vec2 v;
};
layout(binding = 0) uniform UniformBufferObject {
Foo f1;
Foo f2;
} ubo;在这种情况下,f2 的偏移量将为 8,而它应该有 16 的偏移量,因为它是一个嵌套结构。在这种情况下,你必须自己指定对齐方式
struct UniformBufferObject {
Foo f1;
alignas(16) Foo f2;
};这些陷阱是始终明确指定对齐方式的一个好理由。这样,你就不会被对齐错误引起的奇怪症状所迷惑。
struct UniformBufferObject {
alignas(16) glm::mat4 model;
alignas(16) glm::mat4 view;
alignas(16) glm::mat4 proj;
};不要忘记在删除 foo 字段后重新编译你的着色器。