使用异步计算来饱和 GPU
| 此示例的源代码可以在 Khronos Vulkan 示例 github 存储库中找到。 |
计算一切 - 后期处理案例研究
在现代游戏引擎中,计算着色器越来越多地用于执行“所有事情”,除了主通道光栅化。此示例旨在演示一些我们可以用来在基于图块的渲染器(尤其是)上获得最佳行为的技术。正如我们稍后将讨论的那样,由于架构差异,即时模式渲染器的策略有所不同。
在基于图块的延迟渲染器 (TBDR) 上进行计算着色器后期处理的挑战
TBDR 架构将顶点着色和片元着色分为两部分。首先,对顶点进行着色和分箱,一旦完成所有这些操作,就会进行片元着色。一个关键的性能优势是,渲染通道 N + {1, 2, …} 中的顶点着色可以与渲染通道 N 中的片元着色重叠。当针对这些 GPU 上的最佳性能时,我们必须确保永远不会阻塞片元着色。
由于这种渲染架构,这些 GPU 上应该至少有两个硬件队列。
至少在 Arm Mali GPU 上,计算工作负载与顶点着色和分箱在同一个队列中运行。这是直观的,因为顶点着色基本上与计算着色相同,只是添加了一些额外的固定功能魔术。
在这种帧中,计算着色器后期处理变得有问题
-
光栅化通道
-
片元 -> 计算 信号量
-
计算通道
-
计算 -> 片元 信号量 (性能悬崖! :<)
-
渲染 UI + 后输出
-
在图形中呈现
出于两个原因,在图形队列中结束帧是很自然的
-
我们确实希望在渲染到交换链的同一渲染通道中渲染 UI。带宽非常重要,这样可以避免对可以相当大的本机分辨率 UI 图像进行回写和读取。
-
理论上可以在一个计算线程中内联渲染 UI(VK_EXT_descriptor_indexing 肯定会有所帮助!),但这是一个极其复杂的事情。
真正的问题是这里的 计算 -> 片元 信号量。由于 片元 -> 计算 和 计算 -> 片元 屏障,我们有效地阻止了片元在 计算 运行时执行任何工作。如前所述,这是 TBDR 上的性能问题。
队列优先级
锦上添花的是调整队列优先级。队列优先级的行为与实现无关,但其目的是允许驱动程序优先处理一个队列中的工作而不是另一个。在我们的例子中,我们应该将队列 #0 设置为高优先级,将队列 #1 设置为低优先级,因为帧后期进行的工作比下一帧早期进行的工作更重要。从延迟的角度来看,如果队列 #0 可以中断队列 #1,那就最理想了。
手动重新排序过程?
本示例中方法的替代方案是推迟提交 UI + 呈现工作,并在阻塞计算工作之前开始提交下一帧的图形工作。这是有问题的,因为:
-
它增加了处理多个正在进行的帧的复杂性。
-
它增加了不必要的输入延迟。当我们在帧之间增加更多重叠时,我们也会降低响应速度,这对交互式内容非常重要。
示例

该示例实现了一个非常基本的渲染管线,演示了一个合理的渲染场景,包括:
-
以 8K 分辨率渲染定向阴影贴图
-
以 4K 分辨率渲染具有非常基本光照的 HDR 图像
-
在异步计算中进行非常简单和粗糙的 HDR +(非常泛滥的)Bloom 管线
-
在交换链过程中进行色调映射 + UI
这里的目标是利用阴影映射过程,该过程在固定功能光栅化性能方面受到极大的限制。如果我们可以并行进行有用的计算工作,我们应该可以在性能方面获得提升。
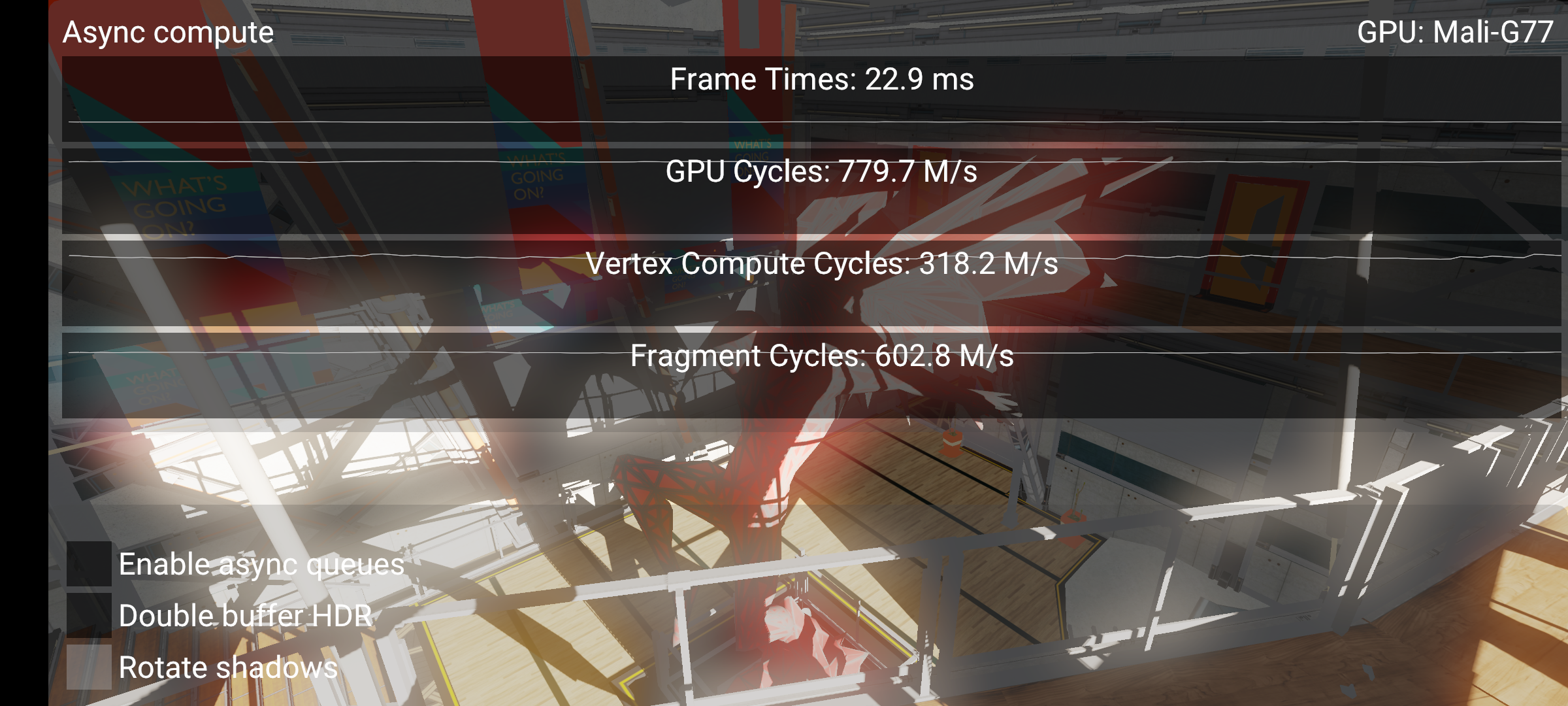
这里我们看到片段周期远低于 GPU 周期。这意味着片段队列的工作量不足。这是由于上面提到的不良屏障造成的。顶点 + 片段周期仍然 > GPU 周期,这意味着存在一些重叠,但这只是顶点着色的重叠。后处理计算使 GPU 工作量不足。
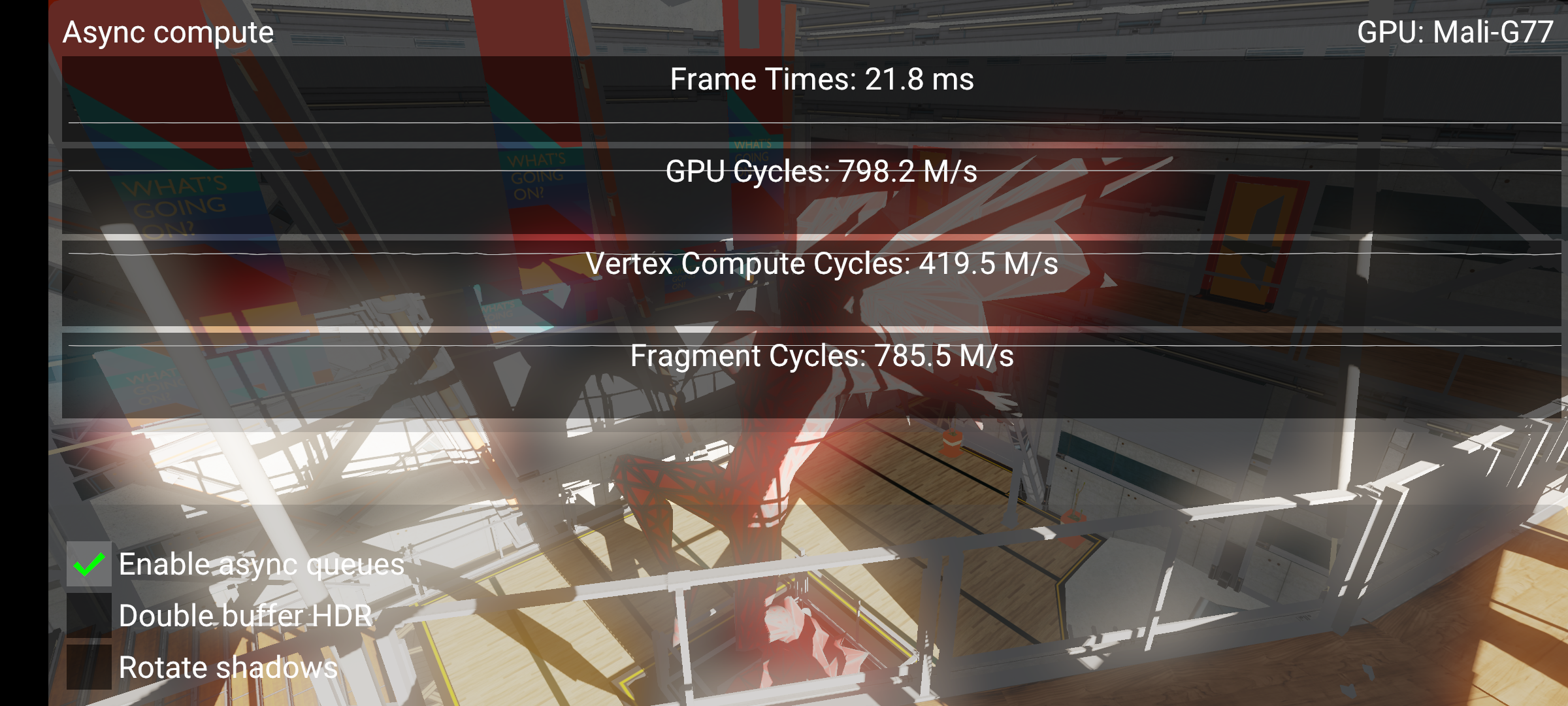
在这里我们可以看到一个不错的性能提升(21.8 毫秒 vs. 22.9 毫秒),并且片段周期现在非常接近 GPU 周期,这意味着没有发生工作量不足的情况。请注意,性能在这里并没有显着提升,我们也不应该期望它会这样。虽然顶点周期和片段周期都增加,但它们仍然在同一着色器核心上竞争资源。我们为获得良好重叠所做的工作意味着 GPU 在硬件队列耗尽工作时,总是有事情可做。