正确使用渲染通道附件
| 此示例的源代码可以在 Khronos Vulkan 示例 GitHub 存储库 中找到。 |
概述
Vulkan 渲染通道使用附件来描述输入和输出渲染目标。此示例展示了加载和存储附件如何影响移动设备的性能。
在创建渲染通道期间,您可以指定各种颜色附件和一个深度模板附件。每个附件都由一个 VkAttachmentDescription 结构体描述,其中包含用于指定 加载操作 (loadOp) 和 存储操作 (storeOp) 的属性。此示例允许您在运行时选择这些操作的不同组合。
VkAttachmentDescription desc = {};
desc.loadOp = VK_ATTACHMENT_LOAD_OP_*;
desc.storeOp = VK_ATTACHMENT_STORE_OP_*;颜色附件加载操作
该示例使用一个颜色附件渲染场景,该颜色附件是用于呈现的交换链图像。由于我们不需要在通道开始时读取其内容,因此使用 LOAD_OP_DONT_CARE 以避免花费时间加载它是合理的。
如果我们不在整个帧缓冲区上绘制,则帧可能会在未绘制的区域显示随机颜色。此外,它将显示在先前帧中绘制的像素。解决方案是使用 LOAD_OP_CLEAR 使用用户指定的颜色清除帧缓冲区的内容。
VkAttachmentDescription color_desc = {};
color_desc.loadOp = VK_ATTACHMENT_LOAD_OP_CLEAR;
// Remember to set the clear value when beginning the render pass
VkClearValue clear = {};
clear.color = {0.5f, 0.5f, 0.5f, 1.0f};
VkRenderPassBeginInfo begin = {};
begin.clearValueCount = 1;
begin.pClearValues = &clear;在这种情况下,使用 LOAD_OP_LOAD 标志是错误的选择。我们不仅在此渲染通道中不使用其内容,而且在带宽方面将花费更多。
以下是使用 LOAD_OP_LOAD 渲染的场景的屏幕截图
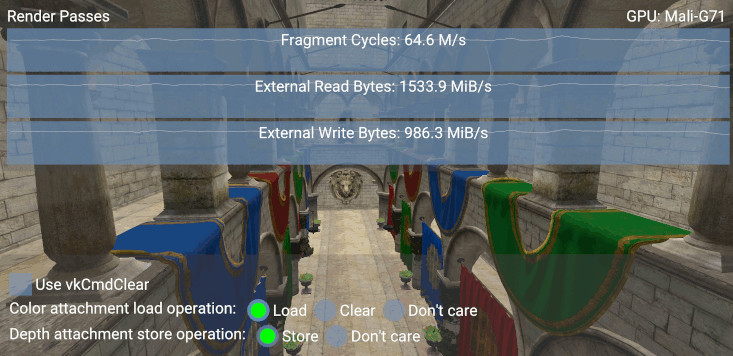
比较读取带宽值(“外部读取字节”图),如果我们选择 LOAD_OP_CLEAR,我们会观察到 1533.9 - 933.7 = 600.2 MiB/s 的差异
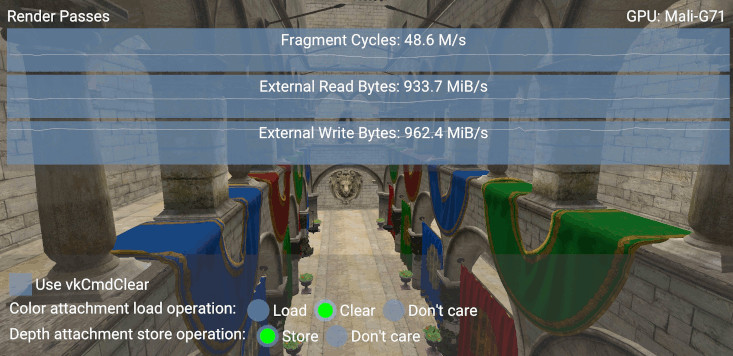
我们可以将加载/存储未压缩附件的带宽成本估计为 width * height * bpp/8 * FPS [MiB/s]。我们计算出的估计值为 2220 * 1080 * (32/8) * ~60 = ~575 MiB/s。如果图像被压缩,节省的量将会减少,请参阅 在 Vulkan 应用程序中启用 AFBC。
深度附件存储操作
渲染通道还使用深度附件。如果我们需要在第二个渲染通道中使用它,则要设置的正确操作是 STORE_OP_STORE,因为选择 STORE_OP_DONT_CARE 意味着第二个渲染通道可能会加载错误的值。示例没有第二个渲染通道,因此没有必要存储深度附件。
VkAttachmentDescription depth_desc = {};
depth_desc.storeOp = VK_ATTACHMENT_STORE_OP_DONT_CARE;值得注意的是,我们可以使用 LAZILY_ALLOCATED 内存属性创建一个深度图像,这意味着只有在实际存储时(通过使用 STORE_OP_STORE)才会由基于瓦片的 GPU 分配它。
VmaAllocationCreateInfo depth_alloc = {};
depth_alloc.preferredFlags = VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT;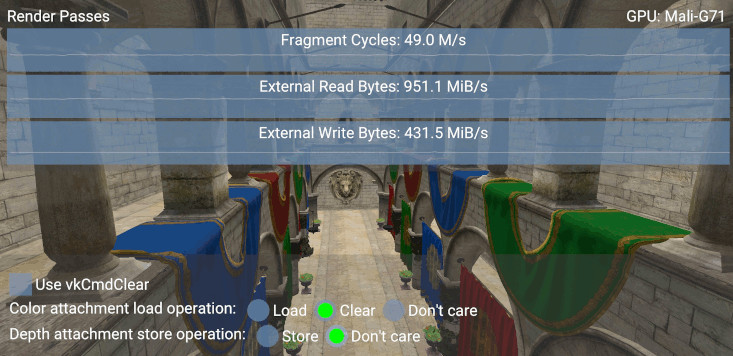
在这种情况下,写入事务减少了 986.3 - 431.5 = 554.8 MiB/s,这再次是我们大致预期的以 ~60 FPS 存储未压缩图像大小所得到的数值。
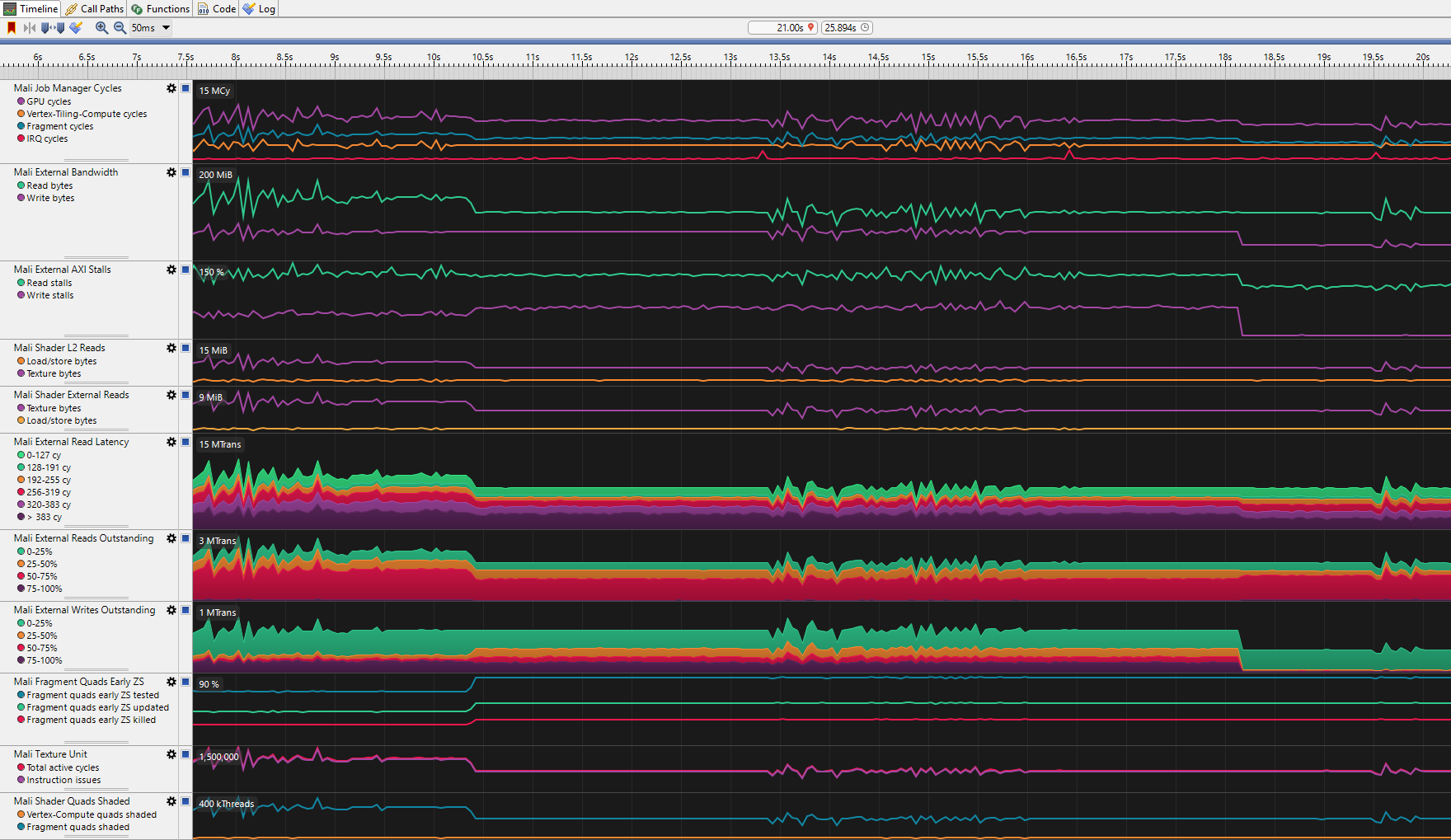
流线轨迹图更深入地分析了 GPU 内部发生的情况。在 10.4 秒处,LOAD_OP_LOAD 和 LOAD_OP_CLEAR 之间的差异很明显,前者外部读取明显更少。在 18.1 秒处,STORE_OP_STORE 和 STORE_OP_DONT_CARE 之间的差异也很明显,外部写入图表直线下降。
vkCmdClear* 函数
使用 vkCmdClear* 来清除附件是不必要的,因为使用 LOAD_OP_CLEAR 可以获得相同的结果。下面的截图显示,通过使用该命令,GPU 每秒将需要大约多 600 万个片段周期。
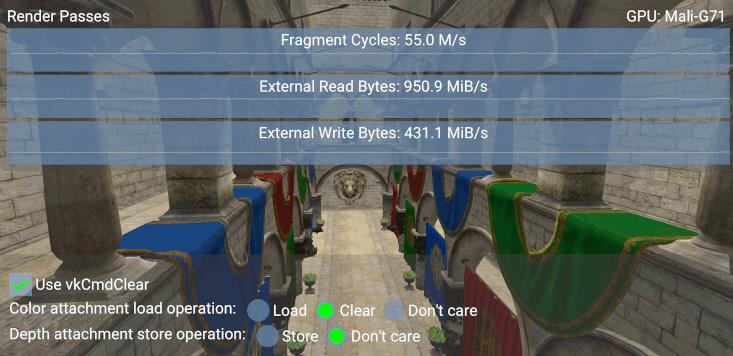
虽然 vkCmdClear* 函数可以用来显式地清除图像,但在某些移动设备上,这将导致每个片段的清除着色器,从而导致上面截图中展示的额外工作负载。尽管如此,vkCmdClear* 函数确实有一些 loadOp 操作无法涵盖的用途,例如 vkCmdClearAttachments 函数可以用来清除渲染过程中附件内的特定区域。
深度图像的使用
除了设置深度图像使用位以指定它可以作为 DEPTH_STENCIL_ATTACHMENT 使用外,我们还可以设置 TRANSIENT_ATTACHMENT 位来告诉 GPU 它可以作为临时附件使用,它只在单个渲染过程中存在。如果它由 LAZILY_ALLOCATED 内存支持,则甚至不需要物理存储。
VkImageCreateInfo depth_info = {VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO};
depth_info.usage = VK_IMAGE_USAGE_TRANSIENT_ATTACHMENT_BIT;渲染区域粒度
应根据 vkGetRenderAreaGranularity 测试提供给渲染通道开始信息结构的渲染区域,以确认它是否为最佳大小。当渲染区域满足以下所有条件时,它才是最佳的:
-
renderArea中的offset.x成员是水平粒度宽度成员的倍数。 -
renderArea中的offset.y成员是垂直粒度高度的倍数。 -
renderArea中的extent.width成员是水平粒度的倍数,或者offset.x+extent.width等于VkRenderPassBeginInfo中帧缓冲区的宽度。 -
renderArea中的extent.height成员是垂直粒度的倍数,或者offset.y+extent.height等于VkRenderPassBeginInfo中帧缓冲区的高度。
最佳实践总结
应该做
-
在渲染通道开始时,使用
loadOp = LOAD_OP_CLEAR或loadOp = LOAD_OP_DONT_CARE清除或使每个附件无效。 -
确保清除时没有屏蔽颜色/深度/模板写入;您必须清除附件的全部内容才能快速清除图块内存。
-
将
VK_ATTACHMENT_LOAD_OP_DONT_CARE标志设置为不作为渲染通道输入的附件。 -
将任何仅在单个渲染通道期间存在的附件设置为由
LAZILY_ALLOCATED内存支持的TRANSIENT_ATTACHMENT,并确保在渲染通道结束时使用storeOp = STORE_OP_DONT_CARE使内容无效。 -
如果您知道自己正在渲染到帧缓冲区的子区域,请使用剪刀框来限制所需的清除和渲染区域。
不应该做
-
不要对以后在渲染通道内使用的任何图像使用
vkCmdClearColorImage()或vkCmdClearDepthStencilImage();将清除操作移至渲染通道loadOp设置。 -
当不需要时,不要在渲染通道内使用
vkCmdClearAttachments(),因为这不像清除或使无效的加载操作那样是免费的。 -
不要通过手动使用着色器程序编写恒定颜色来清除渲染通道。
-
除非您的算法实际上依赖于初始帧缓冲区状态,否则不要使用
loadOp = LOAD_OP_LOAD。 -
不要为渲染通道中实际上不需要的附件设置
loadOp或storeOp;您将为该附件生成不必要的通过图块内存的往返。 -
如果将使用
loadOp = LOAD_OP_LOAD直接在低分辨率游戏帧之上渲染 UI/HUD,则不要使用vkCmdBlitImage作为将低分辨率游戏帧放大到原生分辨率的方法;这将是不必要的内存往返。
影响
-
正确处理渲染通道至关重要;未能遵循此建议可能会导致片段着色性能显着降低,并且由于需要在渲染开始时将未清除的附件读取到图块内存中,并在渲染结束时写出未无效的附件,因此会增加内存带宽。
调试
-
查看 附件描述 的 API 用法。
-
查看 渲染通道创建 的 API 用法,以及
vkCmdClearColorImage()、vkCmdClearDepthStencilImage()和vkCmdClearAttachments()的任何用法。