MSAA (多重采样抗锯齿)
| 此示例的源代码可以在 Khronos Vulkan 示例 github 存储库 中找到。 |
锯齿是欠采样信号的结果。在图形学中,这意味着以导致伪影的分辨率计算像素的颜色,通常是模型边缘的锯齿。多重采样抗锯齿 (MSAA) 是一种有效的技术,可减少像素采样误差。在下图 中,左侧的帧在没有抗锯齿的情况下渲染,而右侧的相同场景使用 4X MSAA。

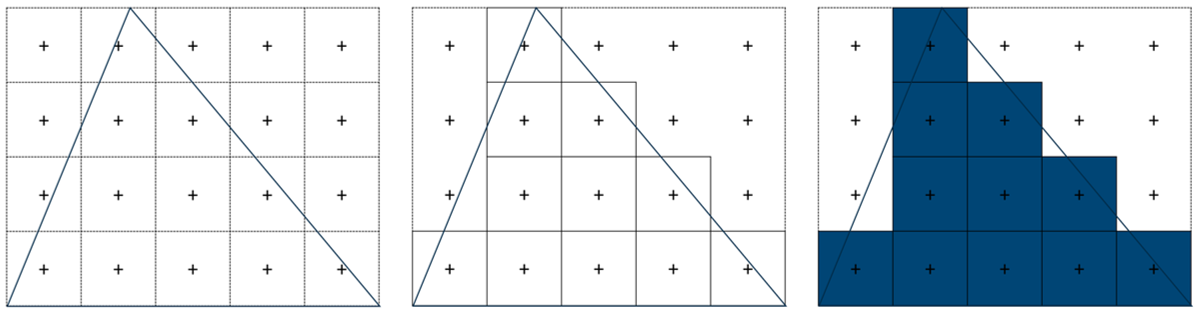
在计算像素的颜色时,如果 GPU 覆盖了像素的中心坐标(并通过了深度测试),则 GPU 将评估给定图元的颜色。如下图所示,在没有抗锯齿的情况下,将为通过此测试的像素评估片段着色器,并相应地进行着色。根据像素密度,此单采样过程可能会导致锯齿。
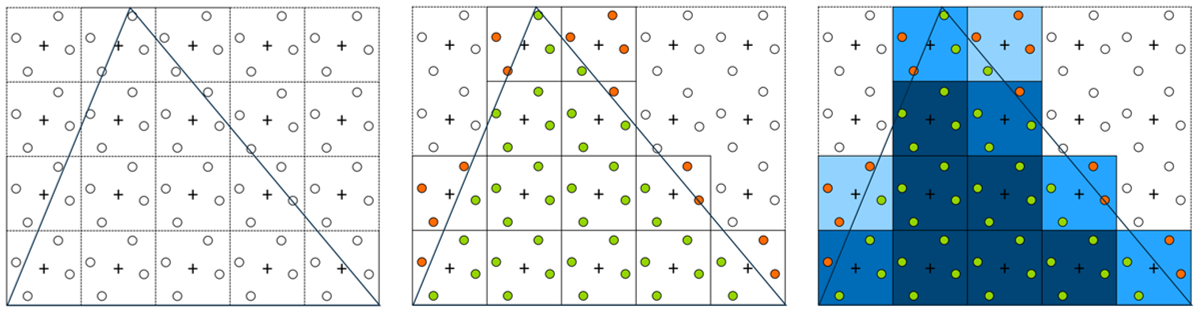
通过多重采样抗锯齿,会在一个像素内测试多个位置。在下图中,有四个采样,因此表示为 4X MSAA。这通过为每个采样存储一个颜色值来有效地增加了每个像素的分辨率。片段着色器仍然只评估一次(使用中心坐标),并且颜色结果存储为位于图元内的那些采样的值(并通过深度测试,这意味着深度缓冲区也需要更大以容纳每个像素的多个值)。换句话说,片段着色器值将被混合到具有覆盖率的所有采样。像素的最终值计算为所有采样的平均值。这称为解析步骤。这会导致边缘处出现不同深浅的图元颜色,从而减少锯齿效果。
MSAA 与超采样抗锯齿 (SSAA) 不同(并且效率更高),在 SSAA 中,为每个采样评估片段着色器。这将有助于减少图元内的锯齿,但通常 mipmap 已经可以缓解这种情况。
要启用 MSAA,首先查询 vkPhysicalDeviceLimits 以选择支持的 MSAA 级别,例如 VK_SAMPLE_COUNT_4_BIT,并在创建多采样附件时以及设置 rasterizationSamples 时使用此成员 pMultisampleState 在图形管线中。如前所述,对于 MSAA,我们不希望设置 采样着色,因为这将启用更昂贵的 SSAA。
颜色解析
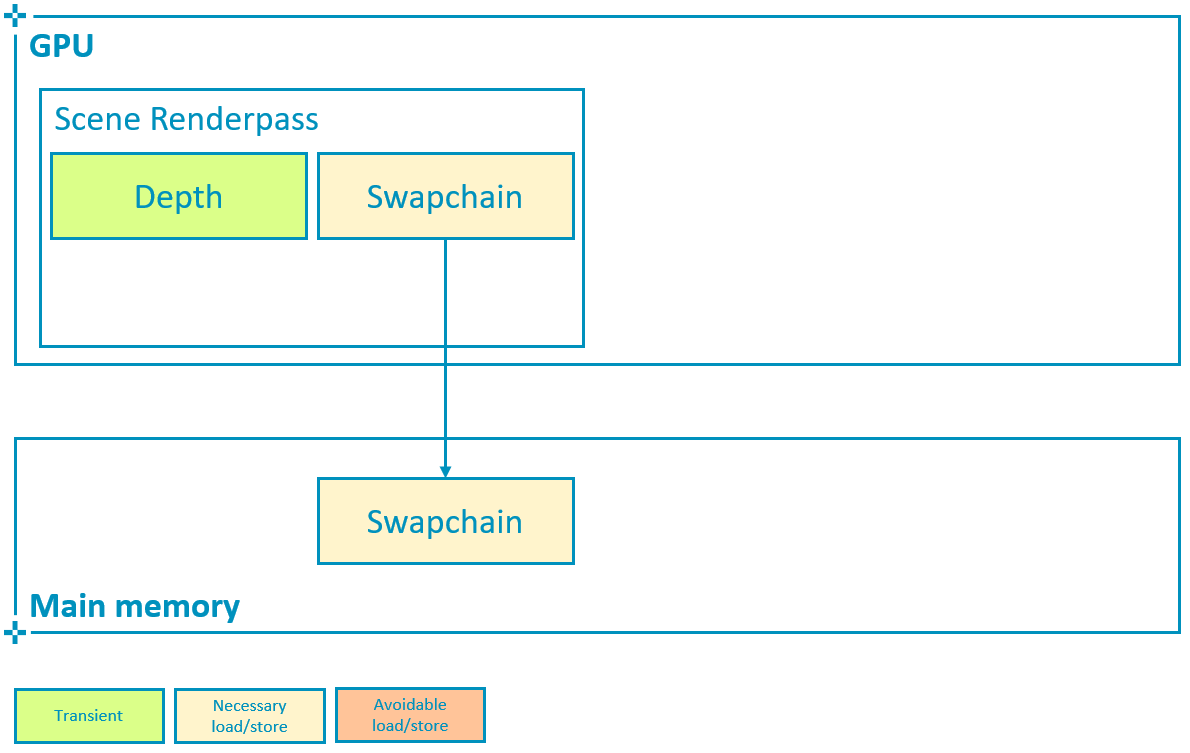

如果渲染场景后不需要使用多重采样附件,则应避免将其写回主内存。这意味着多重采样附件必须使用 storeOp = VK_ATTACHMENT_STORE_OP_DONT_CARE 和 usage |= VK_IMAGE_USAGE_TRANSIENT_ATTACHMENT_BIT,并使用 LAZILY_ALLOCATED 内存属性分配图像,如渲染通道教程中所述。
// Multisampled attachment is transient
// This allows tilers to completely avoid writing out the multisampled attachment to memory,
// a considerable performance and bandwidth improvement
load_store[i_color_ms].store_op = VK_ATTACHMENT_STORE_OP_DONT_CARE;要在写回时解析颜色,如下所示,请配置子通道,使 pResolveAttachments 指向我们希望多重采样颜色解析到的单采样附件,在本例中为交换链图像。
// Good practice
// Enable write-back resolve to single-sampled attachment
subpass->set_color_resolve_attachments({i_swapchain});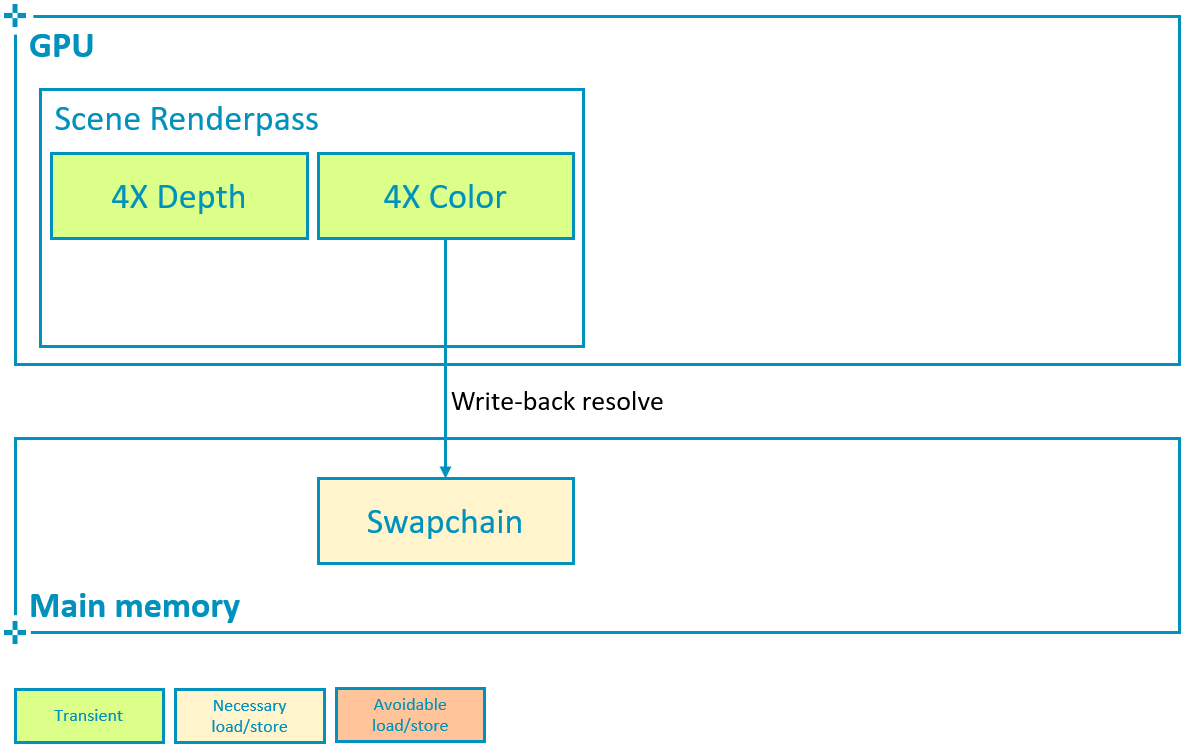

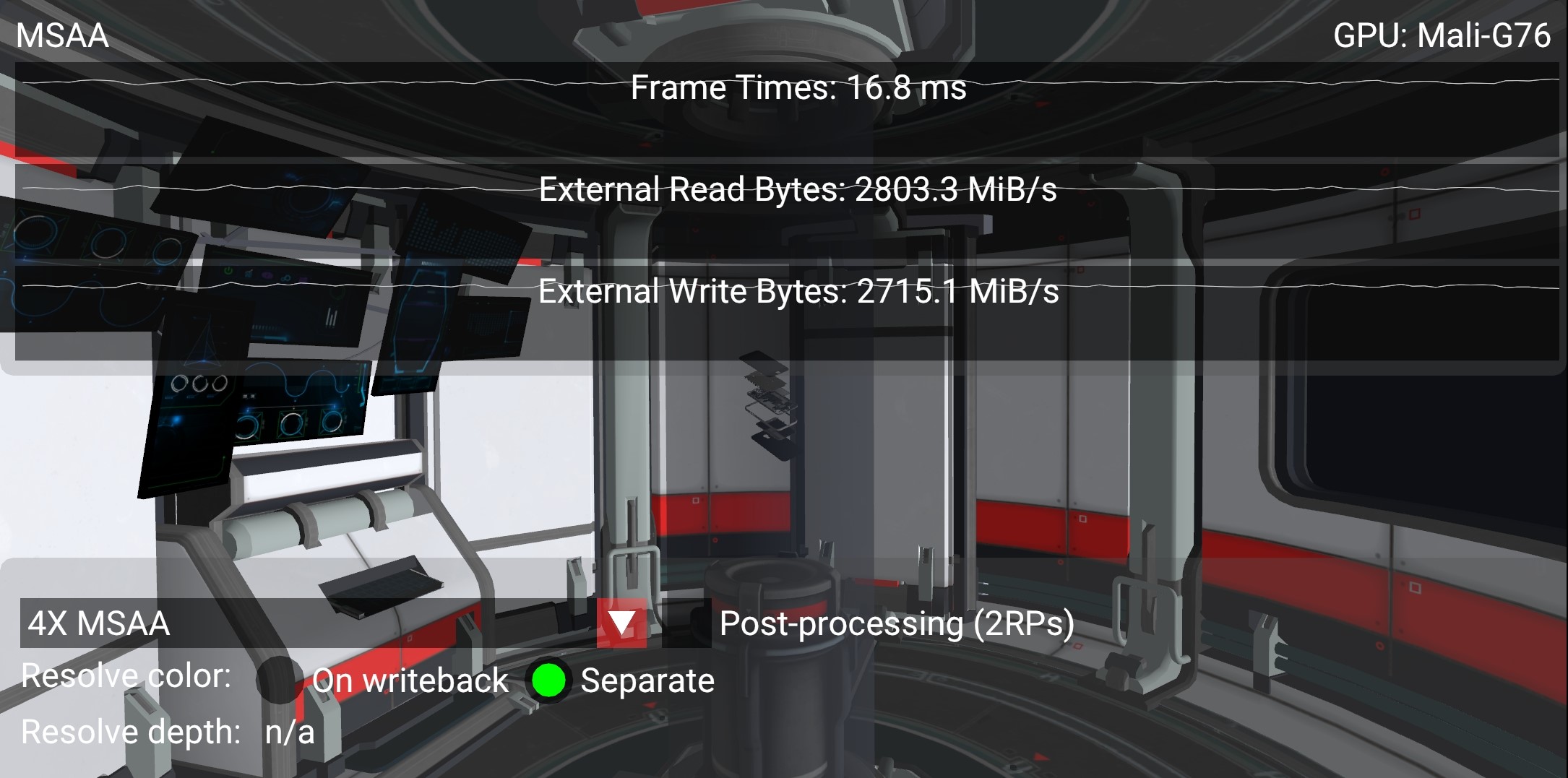
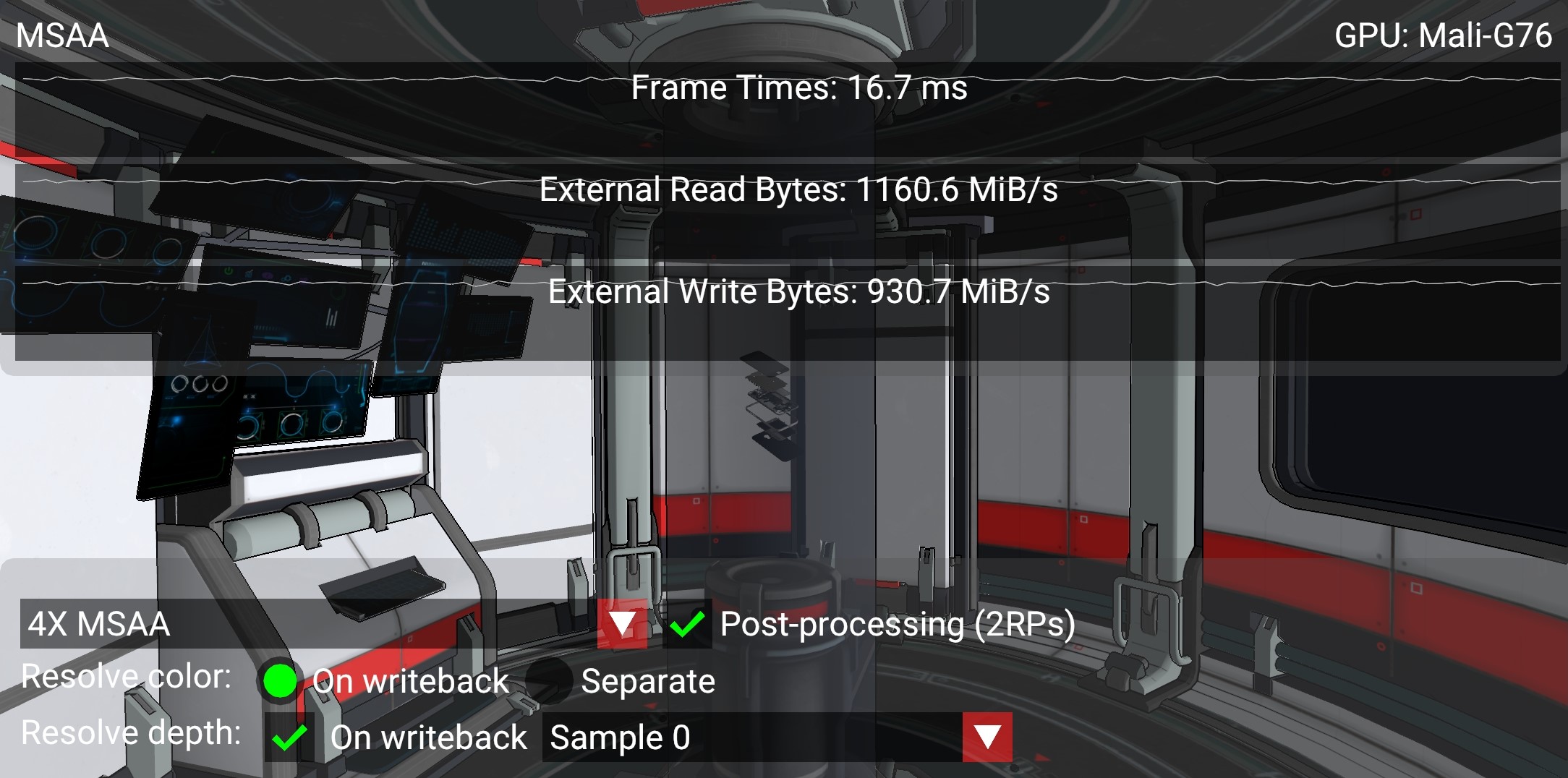
启用 4X MSAA 后,我们将渲染到更大的颜色附件,每个像素存储 4 个颜色值。如果此附件保留在瓦片内存中,则对性能的影响仍然很小(如上面的屏幕截图所示,带宽增加 3%),同时边缘的锯齿明显减少。如前所述,这是因为硬件可以在将图像写回主内存时解析(平均)多重采样附件的采样。
Vulkan 提供了一种替代方法,可以使用 vkCmdResolveImage 显式定义一个单独的颜色附件解析通道。
// Bad practice
// Resolve multisampled attachment to destination, extremely expensive
vkCmdResolveImage(cmd_buf.get_handle(),
multisampled_img.get_handle(),
VK_IMAGE_LAYOUT_TRANSFER_SRC_OPTIMAL,
swapchain_img.get_handle(),
VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL,
to_u32(regions.size()), regions.data());但是,此路径需要在子通道结束时存储多重采样附件(在本例中,该附件比帧缓冲区大 4 倍),然后将其读回 GPU 进行解析。
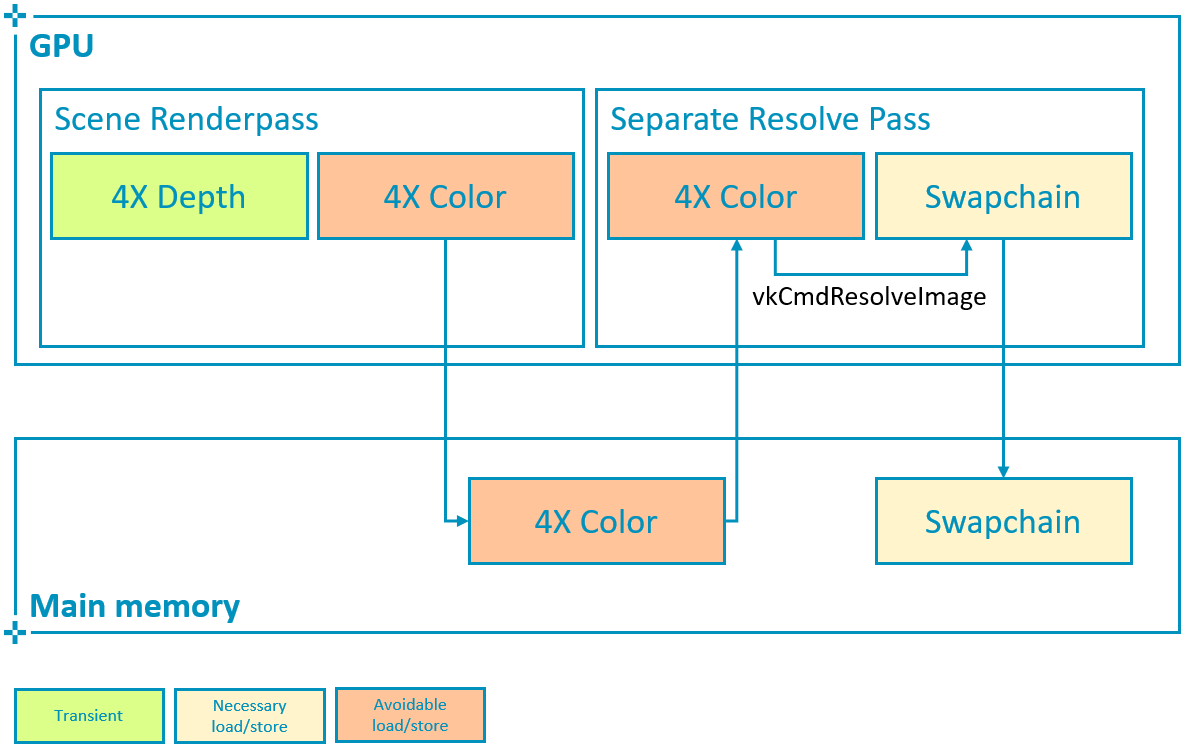
这会消耗更多的带宽,因此,如果可以通过使用 pResolveAttachments 在写回时解析颜色来实现相同的结果,则不建议这样做。为了说明这一点,该示例允许在写回时解析和在单独的通道中解析之间切换,并监控由此对带宽的影响。
在如上面的屏幕截图所示的配备 Mali-G76 的高端智能手机上,带宽差异可以用以下方式解释。该示例以 60 FPS 渲染 2168 x 1080 像素,每个像素需要 32 位(RGBA8,4 字节)。
1X attachment: 2168 * 1080 * 4 * 60 = 562 bytes/s如果我们需要为每个像素存储 4 个采样值,则该值乘以 4。
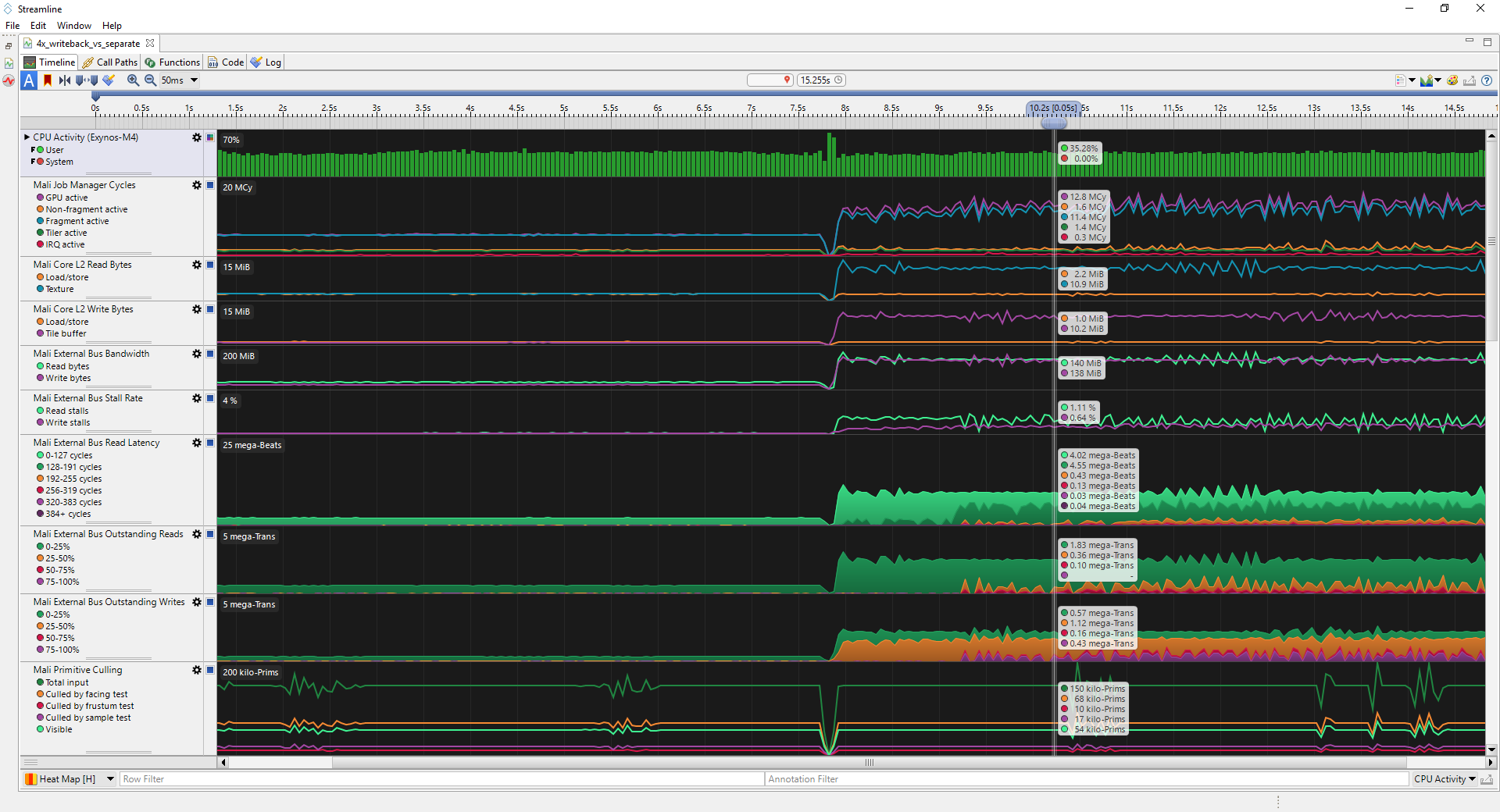
4X attachment: 2168 * 1080 * 4 * 4 * 60 = 2247 bytes/s比较上述屏幕截图中显示的计数器数值,读写带宽都大致增加了 4X 附件的大小,因为多重采样附件需要在场景渲染通道结束时写出,然后重新读取以解析最终颜色。这意味着单独的解析通道会导致带宽增加 5 GB/s。考虑到在像这样的移动设备中,外部 DDR 带宽的成本约为每 GB/s 100 mW,则此开销会消耗 500 mW(20%),而设备功率预算约为 2.5 W,这是非常昂贵的。
这些计数器也可以使用 Streamline 等分析器记录,显示写回时的颜色解析,然后是单独的解析通道。
深度解析
在上述所有情况中,无论是否使用 MSAA,深度缓冲都保持瞬时状态。这是因为一旦计算出颜色并将其写入交换链以显示在显示器上,就可以丢弃深度,因此我们建议配置加载/存储操作以避免将其写出。
在某些情况下,我们可能需要保存深度附件。考虑一个简单的后处理通道,该通道对颜色和深度(绑定为纹理)进行采样,以计算基于屏幕的效果,例如SSAO。
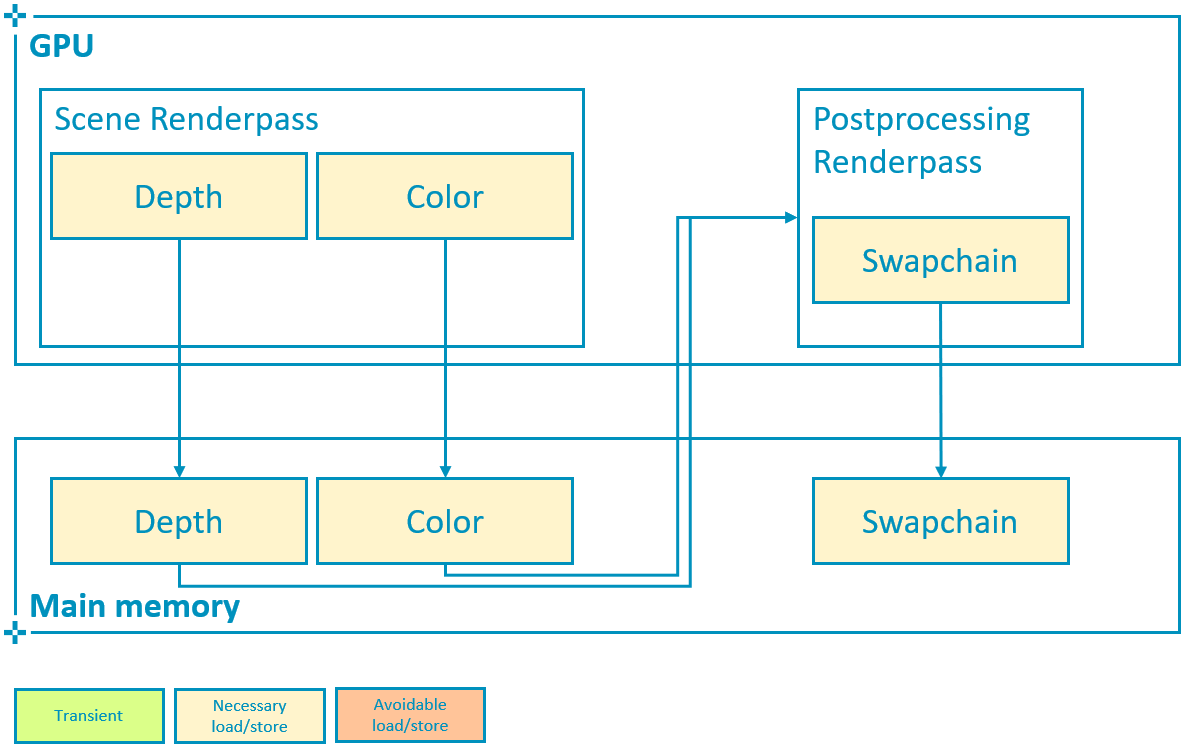

在这种情况下,带宽的增加与写出 2 个全屏附件的带宽相对应,正如预期的那样。使用 4X MSAA 时,只要我们记住在写回时解析颜色和深度,则成本再次几乎保持不变。
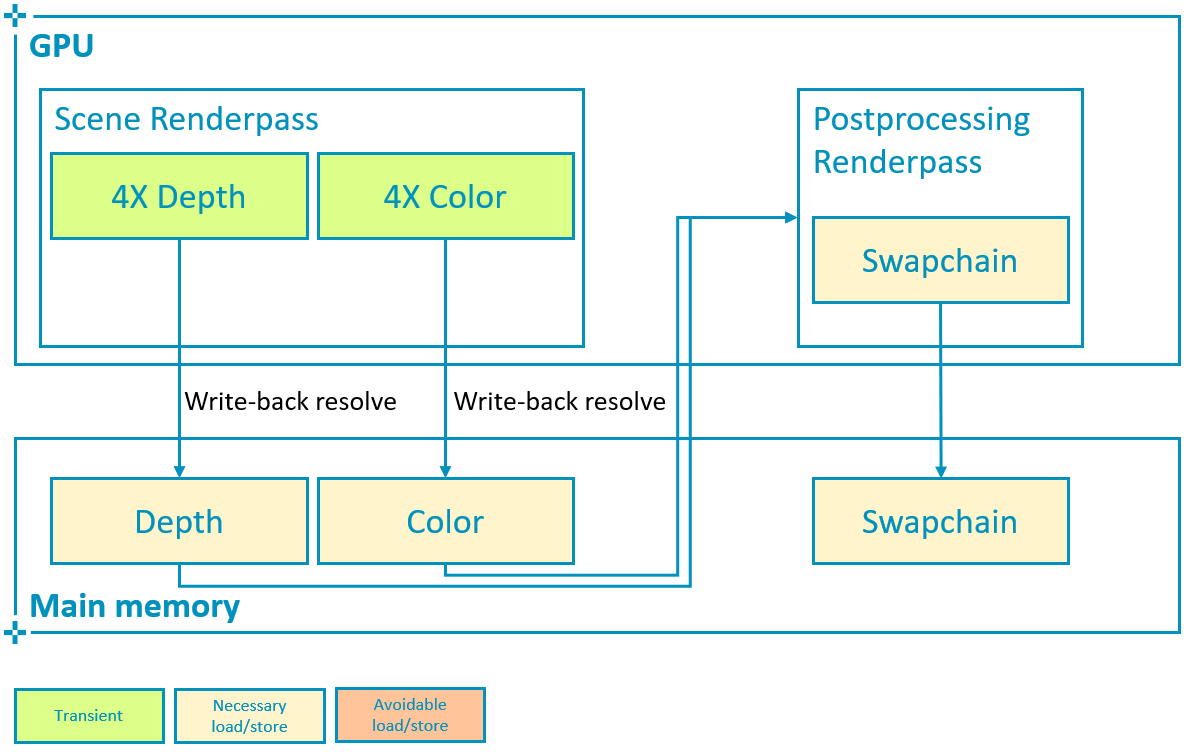
要在写回时解析深度,需要使用 VK_KHR_depth_stencil_resolve(在Vulkan 1.2中进行了提升)。要配置子通道,我们必须使用 VkSubpassDescription2 并使 pNext 指向 VkSubpassDescriptionDepthStencilResolve 结构。此结构定义了将用于解析深度的单采样附件。
// Good practice
// Multisampled attachment is transient
// This allows tilers to completely avoid writing out the multisampled attachment to memory,
// a considerable performance and bandwidth improvement
load_store[i_depth].store_op = VK_ATTACHMENT_STORE_OP_DONT_CARE;
// Enable write-back resolve to single-sampled attachment
subpass->set_depth_stencil_resolve_attachment(i_depth_resolve);
subpass->set_depth_stencil_resolve_mode(depth_resolve_mode);在这里,我们还可以通过将 depthResolveMode 设置为支持的选项之一来选择如何解析深度(该示例查询设备支持的模式并显示下拉选择列表)。
typedef enum VkResolveModeFlagBits {
VK_RESOLVE_MODE_NONE,
VK_RESOLVE_MODE_SAMPLE_ZERO_BIT,
VK_RESOLVE_MODE_AVERAGE_BIT,
VK_RESOLVE_MODE_MIN_BIT,
VK_RESOLVE_MODE_MAX_BIT
} VkResolveModeFlagBits;与颜色相反,Vulkan 不提供解析深度附件的替代方法(vkCmdResolveImage 不支持深度)。因此,如果不支持或未正确配置 VK_KHR_depth_stencil_resolve,则此管线将需要额外读取多重采样深度附件以执行后处理效果。
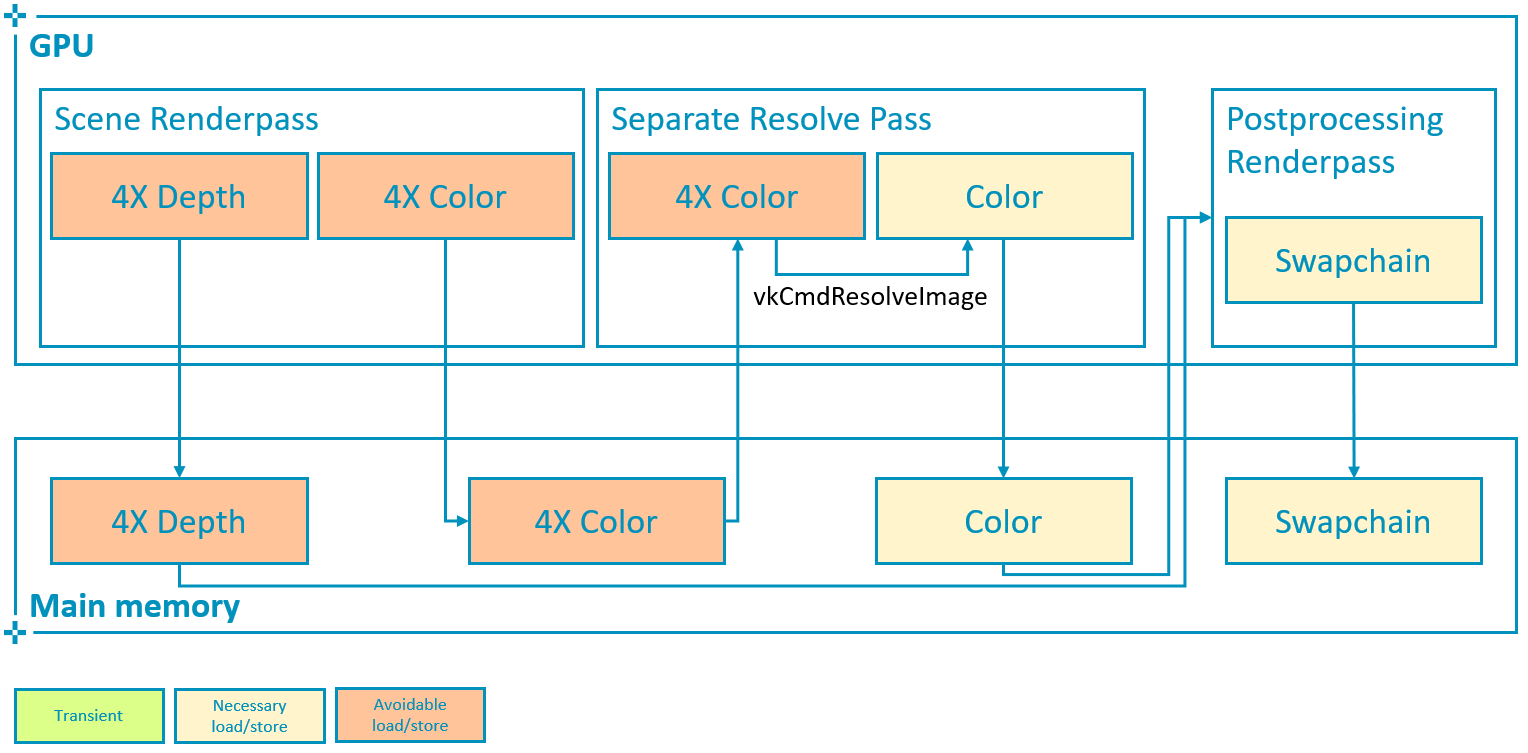
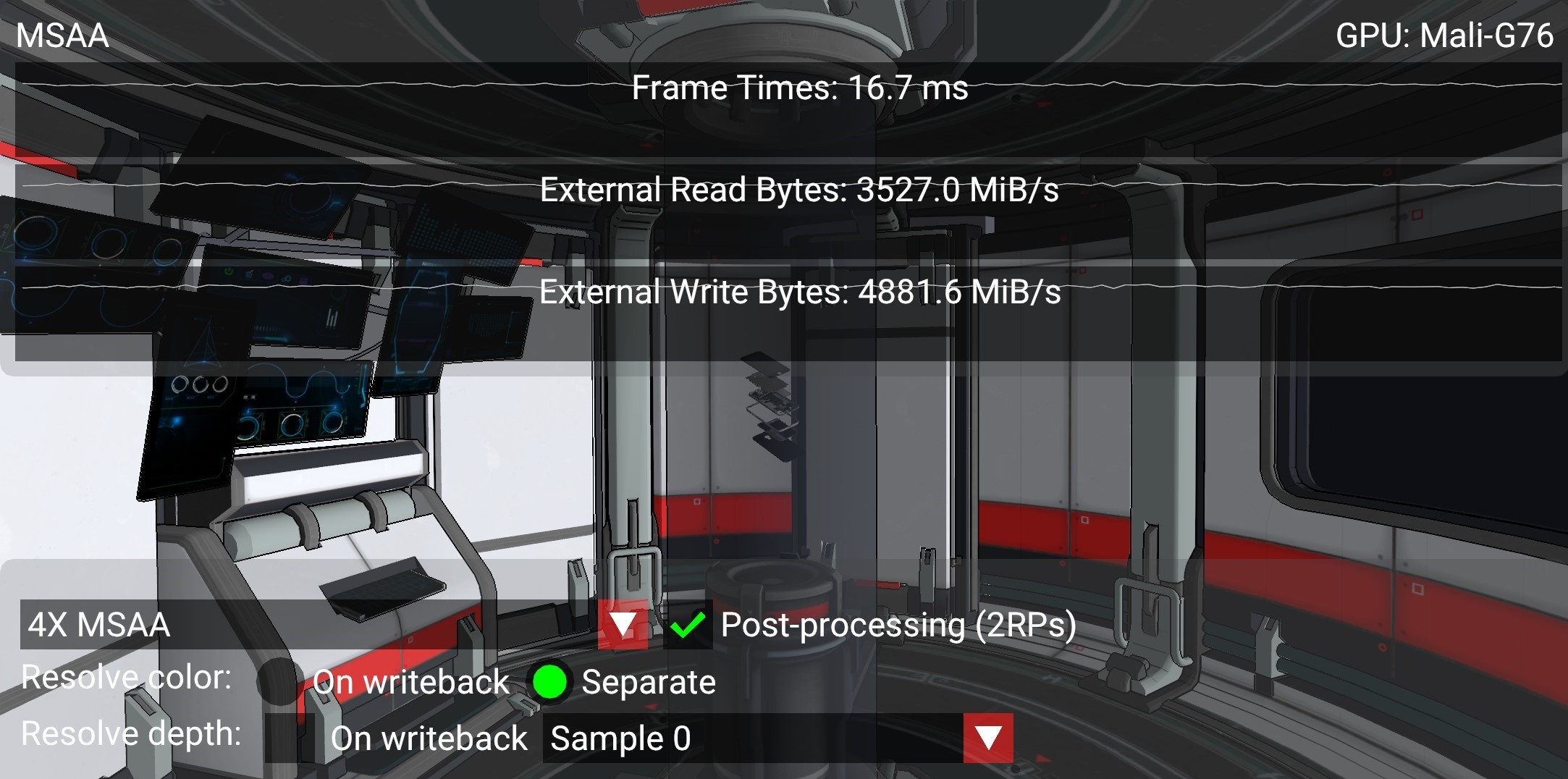
在上面显示的最坏情况下,多重采样深度和颜色都被写入主内存,由于单独解析所需的颜色重新读取,读取带宽增加 2366 MiB/s(接近上面计算的 4X 附件的带宽)。写入带宽增加了 3951 MiB/s,这大致对应于 4X(2247 MiB/s)和 1X(562 MiB/s)深度附件之间的差异(在这种情况下,深度也为 32bpp),即 1685 MiB/s,加上写入额外的 4X 颜色附件所需的带宽,即 2247 MiB/s。总而言之,读/写带宽增加了 6.3GB/s,与写回解析的最佳实践相比增加了 302%,并且可以节省 630 mW 的功率(预算的 25%),从而延长电池续航时间,实现可持续的性能和总体上更好的用户体验。
最佳实践总结
对于多重采样的大多数用途,可以将额外样本的所有数据保留在 GPU 内部的瓦片内存中,并在瓦片写回时将值解析为单像素颜色。这意味着这些额外样本的额外带宽永远不会影响到外部内存,这使其非常高效。MSAA 可以与 Vulkan 渲染通道完全集成,允许在子通道末尾显式指定多重采样解析。
建议
-
如果可能,请使用 4x MSAA;它并不昂贵,并且可以提供良好的图像质量改进。
-
对于多重采样图像,请使用
loadOp = LOAD_OP_CLEAR或loadOp = LOAD_OP_DONT_CARE。 -
对于多重采样图像,请使用
storeOp = STORE_OP_DONT_CARE。 -
使用
LAZILY_ALLOCATED内存来支持分配的多重采样图像;它们不需要持久化到主内存中,因此不需要物理支持存储。 -
在子通道中使用
pResolveAttachments将多重采样颜色缓冲区自动解析为单采样颜色缓冲区。 -
在子通道中使用
VK_KHR_depth_stencil_resolve来自动将多重采样的深度缓冲区解析为单采样的深度缓冲区。通常,这仅在深度缓冲区将被进一步使用时才有用,在大多数情况下,它是瞬态的,不需要解析。
避免
-
避免使用
vkCmdResolveImage();这会对带宽和性能产生显著的负面影响。 -
避免对多重采样图像附件使用
loadOp = LOAD_OP_LOAD。 -
避免对多重采样图像附件使用
storeOp = STORE_OP_STORE。 -
避免在不检查性能的情况下使用超过 4 倍的 MSAA。
影响
-
未能获得内联解析可能会导致更高的内存带宽和性能下降;手动写入和解析 4 倍 MSAA 的 1080p 表面,以 60 FPS 的速度运行,需要 3.9GB/s 的内存带宽,而使用内联解析时仅需 500MB/s。